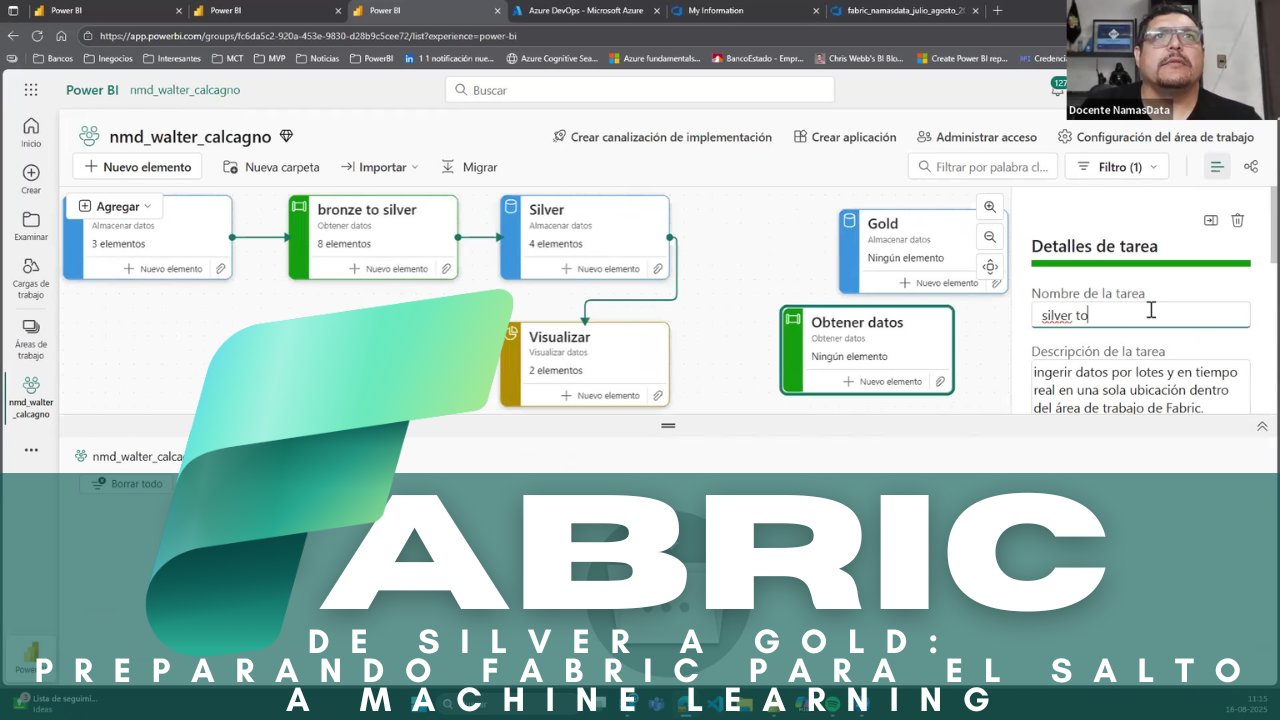
En la cuarta sesión del curso de Fabric en NamasData , Walter Calcagno Lucares nos llevó un paso más allá: pasamos de cultivar la capa Silver a construir y poblar la capa Gold, y abrimos la puerta a machine learning con un flujo reproducible desde notebooks.
La clase combinó criterios de arquitectura (regiones, capacidades, gobierno) con práctica guiada: integración con control de versiones, publicación para consumo y preparación de datos listos para modelar.
Un día muy “end-to-end”: del blueprint a la tabla final en Gold.
Objetivos del día
Walter marcó tres metas nítidas:
- Terminar la capa Gold.
- Trabajar desde notebooks.
- Hacer una primera aproximación a ML.
Lo de streaming y tiempo real quedará para la siguiente sesión. También hubo un guiño a la logística del curso: cinco sesiones y 20 horas totales, con agradecimiento a quienes están usando la capacidad compartida del entorno.
Regiones, capacidades y licencias: decisiones que evitan dolores de cabeza
El módulo operativo comenzó con un tema que suele quedarse “entre bambalinas” y luego pasa factura: cómo elegir la región y la capacidad antes de crear artefactos.
Walter mostró cómo verificar la licencia y la capacidad asociada a un workspace, y explicó por qué conviene fijar la región y el plan desde el inicio.
También introdujo el concepto de regiones emparejadas en Azure y su impacto tanto en la latencia como en los movimientos de artefactos.
La conclusión fue clara: planificar primero, desplegar después.

Del artefacto al código: CI/CD con Azure DevOps
El siguiente bloque estuvo dedicado a versionar artefactos de Fabric y automatizar despliegues.
Walter mostró cómo conectar el workspace a Azure DevOps (Git) para que notebooks, modelos semánticos y demás recursos quedaran como código en un repositorio, habilitando ramas, fusiones y la clásica promoción dev → test → prod.
La lección fue doble:
- Si no hay CI/CD, siempre queda el camino manual (exportar, ajustar IDs y reimportar), pero resulta frágil.
- Con CI/CD el workspace se vuelve declarativo y replicable, lo que necesitamos para trabajar en equipo y sobrevivir a largos ciclos de vida.

¿Puedo consumir el modelo fuera de Fabric?
La respuesta es sí, aunque solo para consumo.
Walter demostró cómo conectar Power BI Desktop a un modelo semántico alojado en Fabric y después publicar un informe en un workspace que no es de Fabric.
El matiz es clave: si apagas Fabric, el modelo deja de actualizarse y solo queda disponible la última versión publicada.
Este patrón resulta útil cuando necesitas ofrecer informes a áreas que no usan Fabric, pero quieres que el modelo siga gobernado y centralizado en la plataforma principal.
Construyendo la capa Gold
Con los cimientos preparados, llegó el momento de crear la sección Gold (Lakehouse) y dejar claro su propósito: albergar datos listos para consumo avanzado, ya sea en analítica tradicional, inteligencia artificial o machine learning.
Walter subrayó que el diagrama de tareas en Fabric debe entenderse como un flujo lógico y no necesariamente como un orden estricto de ejecución: Bronze → Silver → (visualización) → Gold.
La capa Gold se convierte en el escaparate de datos: tablas con nomenclatura clara, esquemas estables y listas para ser consumidas por visualizaciones, predicciones o cualquier otro escenario de negocio.

Semantic Link desde notebooks: explorar sin duplicar
En el notebook, Walter presentó la librería Senpai (Semantic Link) como herramienta para explorar el modelo semántico directamente como fuente de datos.
Gracias a esta librería, es posible listar modelos, tablas y columnas sin necesidad de re-orquestar orígenes ni duplicar información.
La idea central es potente: evitar redundancias y construir features directamente sobre lo ya curado en el modelo semántico de Silver, preparando una salida depurada para la capa Gold y para futuros entrenamientos de machine learning.
Además, se mostró cómo Copilot en notebooks puede acelerar la escritura de fragmentos de código y facilitar las pruebas en tiempo real.
DataFrames, filtros y joins: de Silver a un dataset de entrenamiento
La práctica siguió un camino muy reconocible para cualquiera que haya montado un pipeline de features:
- Leer la tabla de hechos del modelo semántico y previsualizar registros.
- Filtrar por un rango temporal para acotar el entrenamiento.
- Unir con dimensiones (como estaciones meteorológicas) para enriquecer los datos con nombres y atributos.
- Estandarizar tipos y campos para dejar una estructura simple y lista para modelar.
Walter remarcó un detalle clave: en Fabric conviven distintos tipos de DataFrame (Fabric, Spark, pandas). Si quieres aprovechar transformaciones de Spark, hay que convertir explícitamente a Spark DataFrame antes de aplicar funciones como withColumn, filter o join.

Persistencia en Gold: la mesa está servida
Con el dataset listo, el paso final fue guardarlo como tabla en la capa Gold utilizando comandos como saveAsTable con la opción overwrite.
De esta manera, el resto del equipo puede acceder con nombres estables y permisos controlados, garantizando consistencia en el consumo de datos.
Este cierre operativo es lo que permite que visualizaciones, notebooks de predicción y otros consumidores trabajen todos sobre la misma verdad.
Comunidad, certificación y lo que viene
En el tramo final, la conversación giró hacia la certificación DP-700. El contenido medular está cubierto, pero Walter recalcó que la práctica constante es la que marca la diferencia a la hora de aprobar.
También explicó cómo descargar notebooks y artefactos para conservarlos una vez terminado el periodo de uso del tenant.
Por último, adelantó los contenidos de la próxima clase: streaming y tiempo real, junto con aspectos de administración y costes, para cerrar el arco del curso con una visión más operativa.

Qué me llevo de esta clase
- Arquitectura antes de picar código: región, capacidad y gobierno definen el éxito operativo.
- Todo como código: llevar artefactos de Fabric a Git nos da reproducibilidad, calidad y tranquilidad.
- Semántica primero: si el modelo ya curó los datos, úsalo como fuente y evita duplicarlos.
- Gold con propósito: una tabla clara y estable vale más que un pipeline ingenioso pero opaco.
Nos vemos en la clase 5 en NamasData 🤗
Puedes leer la serie sobre Fabric aquí: https://blog.alexayala.es/category/fabric/


Deja un comentario